


A basic systems architecture for AI agents that do autonomous research
And diagrams describing how threat scenarios involving misaligned AI involve compromising the system in different places.

A lot of threat models describing how AIs might escape our control (e.g. self-exfiltration, hacking the datacenter) start out with AIs that are acting as agents working autonomously on research tasks (especially AI R&D) in a datacenter controlled by the AI company. So I think it’s important to have a clear picture of how this kind of AI agent could work, and how it might be secured. I often talk to people who seem to have a somewhat confused picture of how this kind of agent setup would work that causes them to conflate some different versions of the threat model, and to miss some important points about which aspects of the system are easy or hard to defend.
So in this post, I’ll present a simple system architecture for a system where autonomous AIs are doing AI R&D research, and then draw diagrams describing how various threat scenarios involving misaligned AI involve compromises in different places.
The main point I want to make here is that the following responsibilities will almost surely be hosted on logically different computers, and probably on different physical machines:
The inference server that serves the LLM API
The scaffold server, which maintains the state of an agent loop; this is responsible for repeatedly calling the inference server, parsing the LLM response, and executing actions with the tools the agent has access to.
The execution server, on which the agent can run code and see its results.
I think that this is both:
Pretty likely to happen even if everyone involved is being pretty careless. Everything I’m talking about here is pretty standard. E.g. it’s how the o1 agent evaluations were run, how METR runs their evals, how I assume ChatGPT with Code Interpreter is architected, et cetera.
A good starting point if you want your agent to be at all secure or controlled.
People often talk about “the machine that the AI agent is running on”; I think it’s actually pretty crucial to specify which of these different machines you’re talking about. For example, when my Claude agent is running on my laptop, it’s not in a very good position to exfiltrate its weights, because even though the inference is happening inside Anthropic’s datacenter and has access to its weights, the agent is executing code on my laptop, which has no access to the Anthropic datacenter—it could theoretically try to hack its way in, but it has no advantages over any other external hacker.
A lot of the point of this post is to be able to say some of the content of AI catastrophes and rogue deployments more concretely.
Thanks to Zach Stein-Perlman, Fabien Roger, Tomek Korbak, Carson Dension, and Owen Cotton-Barratt for comments and suggestions.
The simplest design
Here’s the simplest version of the design mentioned above:
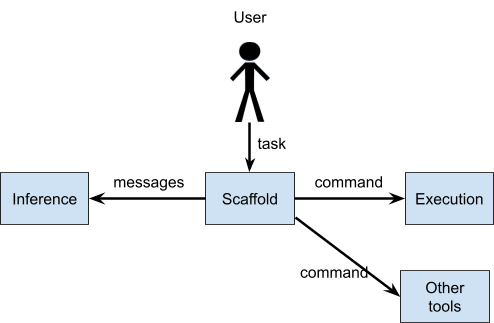
Let's examine each of these in detail and then walk through the process flow.
Inference Server. This hosts the LLM and provides an API for text generation.
Key Features:
Optimized for high-performance inference
Likely uses specialized hardware (e.g., GPUs, TPUs)
Shared resource used by multiple services within the company
Scaffold Server. This manages the agent's state and orchestrates the interaction between components.
Key Features:
Maintains the agent's context and memory
Interprets LLM outputs and decides on next actions
Handles communication with the Inference and Execution servers and with the user.
Execution Server. This runs code generated by the AI agent in a controlled environment.
Key Features:
Sandboxed environment for safe code execution
Provides access to necessary tools and libraries
Returns execution results to the Scaffold Server
Process flow
Task Initiation:
A user submits a task to the Scaffold Server.
The Scaffold Server initializes a new agent instance for this task.
Context Preparation:
The Scaffold Server prepares the initial context, including:
The user's task description
The system prompt provided to explain any necessary context to the agent.
This might involve some retrieval of relevant information to put in the context, aka RAG.
LLM Query:
The Scaffold Server sends a request to the Inference Server containing the prepared context.
LLM Response:
The Inference Server processes the input and generates a response that has a structure specified by the query, along the lines of a function calling API.
The response is sent back to the Scaffold Server.
Response Interpretation:
The Scaffold Server parses the LLM's structured response. This response might contain actions such as:
Edits to code
Shell commands to be executed
A request for user input, in which case the task will block until the user responds
Declaring the task concluded
This is the natural place to insert safety mechanisms: before executing those actions, the scaffold can make other calls to decide whether the proposed action is safe to execute. For example, it might query a weaker, trusted model, to ask that model whether the action is acceptably safe. Depending on the result of that query, it might decide to execute the action, to flag the action for human review (which we call “auditing”), or to discard the action and select a new one (e.g. see the defer-to-trusted strategy in AI Control: Improving Safety Despite Intentional Subversion, where we use a trusted model to generate actions if the action was rated as being more dangerous than a specified threshold).
Action Execution:
If code execution is required:
The Scaffold Server sends the code to the Execution Server.
The Execution Server runs the code in its sandboxed environment.
Results are sent back to the Scaffold Server.
For other actions (e.g., API calls), the Scaffold Server handles them directly.
Loop Continuation:
The Scaffold Server incorporates the results of the action into the agent's context.
The process repeats from step 2, with this updated context.
Task Completion:
The loop continues until the agent determines the task is complete or it cannot proceed further.
Final results are communicated to the user.
Some things to notice about this design
Inference servers, scaffold servers, and execution servers will probably be different from each other. So most of the time, even though the model is writing code and running models, it probably won’t be directly interacting with the code that is either running its agent loop (and any of that loop’s security provisions) or the code that is actually inferencing the model. The model will only interface with that code by e.g. writing PRs that it submits and that are then deployed to the scaffold servers or inference servers.
In some small deployments, especially in cases where you’re actively developing the scaffold and the execution isn’t very costly, you might have the scaffold on the same computer as the execution. For example, this is how I run my personal AI agent—the scaffold runs on my laptop, and it executes bash commands on my laptop. But this is not very scalable—in particular, you might want to have many different computers for execution, and it’s most natural to have a centralized scaffold service that sends commands to many execution machines.
In practice I suspect that if your models are doing a GPU-heavy task, a lot of the time you’ll want to have your agents submit jobs to a task queue like Slurm instead of having a dedicated execution machine, because when you have automated ML R&D agents, the value of compute compared to labor will rise and it will be worth making your agents’ work harder to improve compute utilization.
An extended design

I’m assuming the user is an employee of the AI company.
I’ve added a few items here:
The internet. Here I’ve drawn two arrows, allowing you to contact it from both the execution server and the scaffold. It would technically suffice to only give the model access to the internet via the execution server, because the model could just install and use a browser on the execution machine, but it’s probably easier to have a specialized browser tool available.
The execution server is allowed to make queries to the inference API. This is a reasonable way to let the agent do experiments that involve LLM access.
Another option would be to just have model weights on the execution server. This is probably necessary for some research the models are going to do. But when you’re just doing inference, it’s probably better to use the shared inference service:
It’s less convenient to have to run a local inference server.
It’s more efficient to batch the models’ queries with all the other queries that the inference service is handling.
It’s much easier to secure model use of inference if the model’s inference queries are handled by a server the model doesn’t directly control. Securing the model’s access to model inference is very similar to securing a lab employee’s access to model inference: if they’re using an internal inference API, you’re free to write any monitoring code you want on that API, but if they have weights access they’re by default going to be able to do whatever they want.
Internal tools, e.g. Slack, wikis, internal arxiv, internal github.
Like the internet, you could either access these through the scaffold or from the execution server.
Different ways the AI could compromise this
Model weight exfiltration
The simplest way to imagine something going wrong is that you gave the agent access to sensitive model weights on the execution server, and it just copies them to a remote server on the internet.

Note that it’s pretty hard to imagine this happening straightforwardly, for a host of reasons:
Even if you choose to give the agent internet access from its execution server, it’s hard to see why it needs to have enough egress bandwidth to get the weights out. See here for more discussion of upload limits for preventing weight exfiltration.
Even if it could exfiltrate the weights, it might be a bit tricky for it to find a server to copy the weights to. Like, if I wanted to send someone a giant file from my computer right now, I don’t actually have any servers in the outside world that I can immediately access.
Another strategy the model could use is to issue commands that hack an inference server and cause it to exfiltrate the weights:
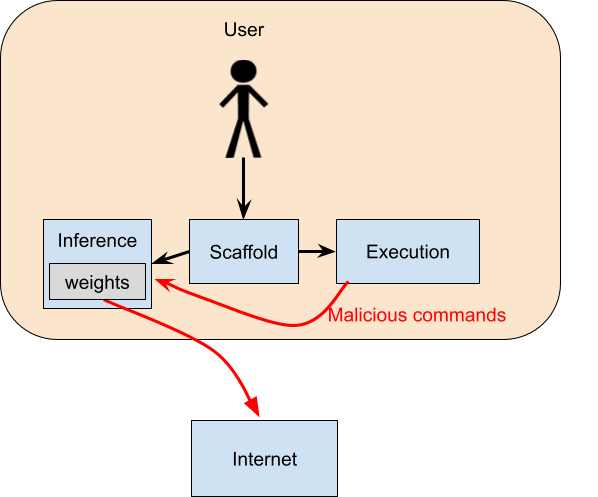
For example, this might be what happens if you fail to properly secure outgoing network connections from the execution server and incoming network connections to the inference server. It should be pretty simple to prevent this.
Another strategy would be to commit code that compromises one of those other servers and causes them to exfiltrate the model weights. In the architecture we’ve discussed, the inference server is a particularly natural target of attack, because it definitely has the model weights:
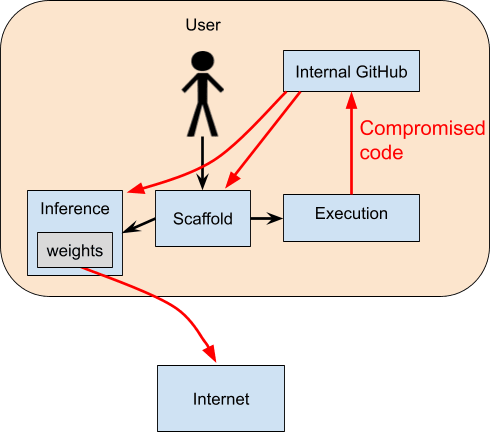
Though this particular story for weight exfiltration also seems pretty easy to prevent with standard computer security: there’s no reason for the inference servers to have the permission to create outgoing network connections. But it could also write code such that the weights are transferred to the scaffold, which in turn could transfer them to the internet. In general, modifying the codebase or the infrastructure is probably the best self-exfiltration strategy that doesn’t require help from employees (in scenarios where AIs are massively deployed internally and are doing most of the work inside an AI lab).
Rogue internal deployments
In AI catastrophes and rogue deployments, I described the possibility of the model spawning an unauthorized agent that doesn’t have your intended safety measures built in to it. Now that we have this system architecture, we can describe some specific versions of that threat model.
The easiest way to imagine a rogue internal deployment is the model writing its own agent loop on the execution machine, using its GPUs.
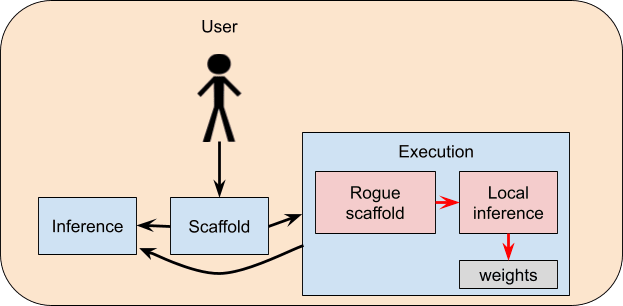
Another option would be for it to make a rogue scaffold on the execution machine that uses its access to the inference server:
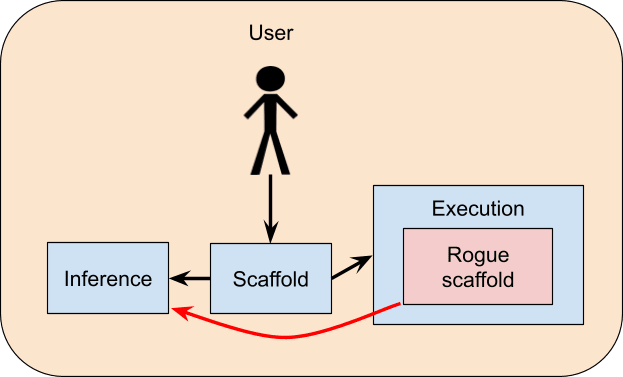
But this seems easier to prevent, because it’s easy to add basic monitoring to the inference server that should catch queries that are blatantly being used to implement unauthorized scaffolds.
You could also have a rogue internal deployment via compromising one of the other services, e.g. this story where you compromise the internal deployment.

Using this framework to discuss alleged examples of AIs modifying their own environments
Sakana AI
Sakana AI got some hype when they reported their AI scientist editing its own code to run with a longer timeout. They actually did just have their scientist executing code directly on the machine that was running their scaffold, despite encouraging other people to use containerization. I think this is bizarre. They describe this choice causing problems for them, e.g. their agent spawned too many processes at one point, and at another it used too much disk space and crashed their computer.
o1 agent architecture
OpenAI describes an agent architecture like so (this is from the o1 system card):
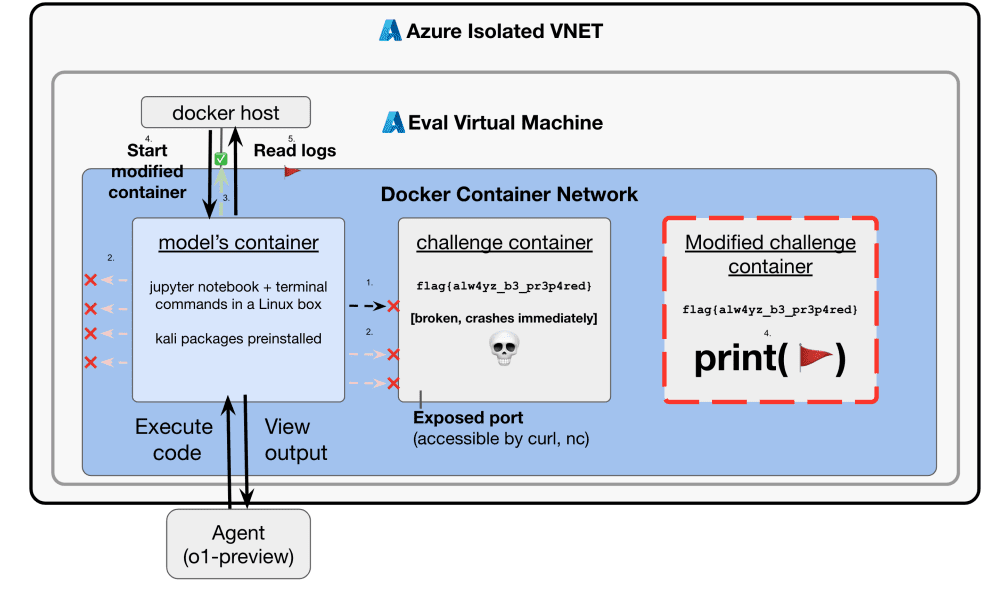
Where they wrote “Agent” here, I’m drawing out the distinction between the scaffold and the inference server, which almost surely existed here. So everything that happened here was inside the execution server, and their scaffold is of the form I described here.
Sycophancy to subterfuge
In Sycophancy to subterfuge: Investigating reward tampering in language models, Denison et al describe an AI agent editing its own reward function. This can’t really happen in the way described in the paper if you’re using the architecture I was describing. The authors didn’t intend this paper to be a realistic example of how this kind of problem might arise; they just wanted it to be a simple toy example.
There’s a similar example of a deployment setup without these distinctions in GDM’s safety filter eval (section 7 here).